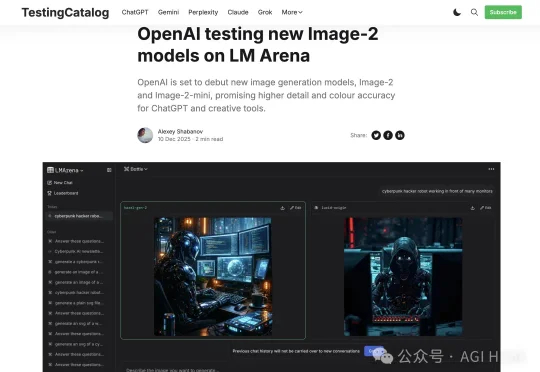
OpenAI 新图像模型 GPT-Image-2 泄露
OpenAI 新图像模型 GPT-Image-2 泄露OpenAI 的下一代图像模型 GPT-Image-2,今天在 Chatbot Arena 上被人发现了。独立开发者 levelsio 率先爆料,这个模型以三个代号悄悄上线了 Arena:maskingtape-alpha、gaffertape-alpha、packingtape-alpha。
来自主题: AI资讯
9968 点击 2026-04-04 22:38
 搜索
搜索
OpenAI 的下一代图像模型 GPT-Image-2,今天在 Chatbot Arena 上被人发现了。独立开发者 levelsio 率先爆料,这个模型以三个代号悄悄上线了 Arena:maskingtape-alpha、gaffertape-alpha、packingtape-alpha。
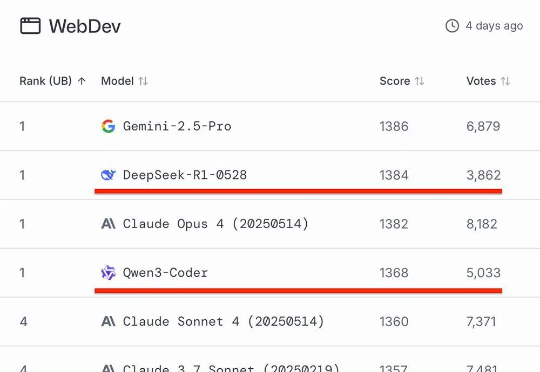
知名AI大模型评测Chatbot Arena放榜!阿里Qwen3-235B-A22B-Instruct-2507位列大语言模型总榜第三,月之暗面Kimi-K2-0711-preview、深度求索DeepSeek-R1-0528并列为总榜第五,以开源之姿超越Claude 4、GPT-4.1等顶尖闭源模型。
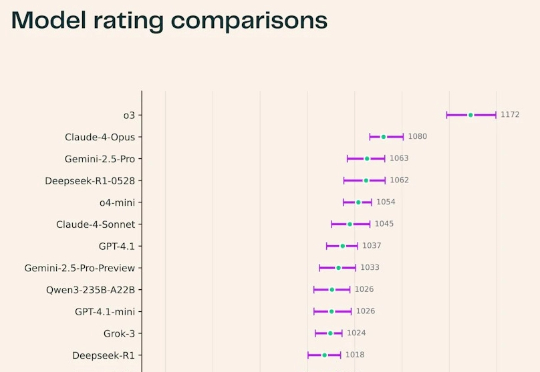
最近,Ai2耶鲁NYU联合推出了一个科研版「Chatbot Arena」——SciArena。全球23款顶尖大模型火拼真实科研任务,OpenAI o3领跑全场,DeepSeek紧追Gemini挤入前四!不过从结果来看,要猜中科研人的偏好,自动评估系统远未及格。

你信任的AI排行榜,可能只是一场精心策划的骗局!震惊业界的Cohere Labs最新研究彻底撕破了Chatbot Arena这一所谓"黄金标准"的华丽面纱,揭露了科技巨头们如何肆无忌惮地操控评估系统、掠夺社区资源、扼杀开源创新。
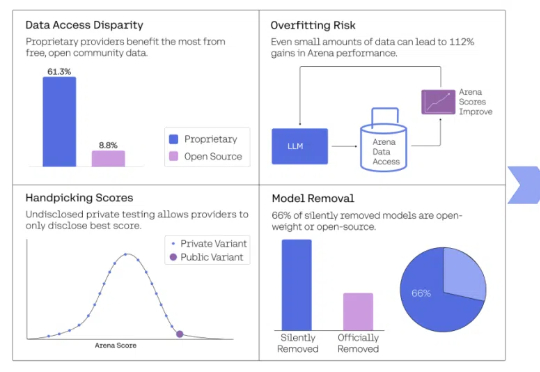
大模型竞技场的可信度,再次被锤。
作为学术研究项目,原加州大学伯克利分校的Chatbot Arena,其网站已成为访客试用新人工智能模型的热门平台,现正转型为独立公司。
Llama 4真要被锤爆了,这次是大模型竞技场(Chatbot Arena)官方亲自下场开怼:
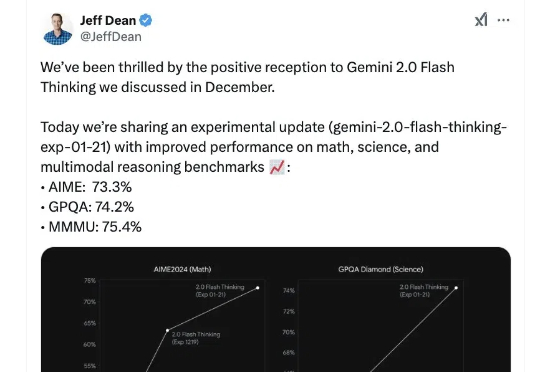
就在国内各家大模型厂商趁年底疯狂卷的时候,太平洋的另一端也没闲着。 就在今天,谷歌发布了 Gemini 2.0 Flash Thinking 推理模型的加强版,并再次登顶 Chatbot Arena 排行榜。

今年 6 月底,谷歌开源了 9B、27B 版 Gemma 2 模型系列,并且自亮相以来,27B 版本迅速成为了大模型竞技场 LMSYS Chatbot Arena 中排名最高的开放模型之一,在真实对话任务中比其两倍规模以上的模型表现还要好。
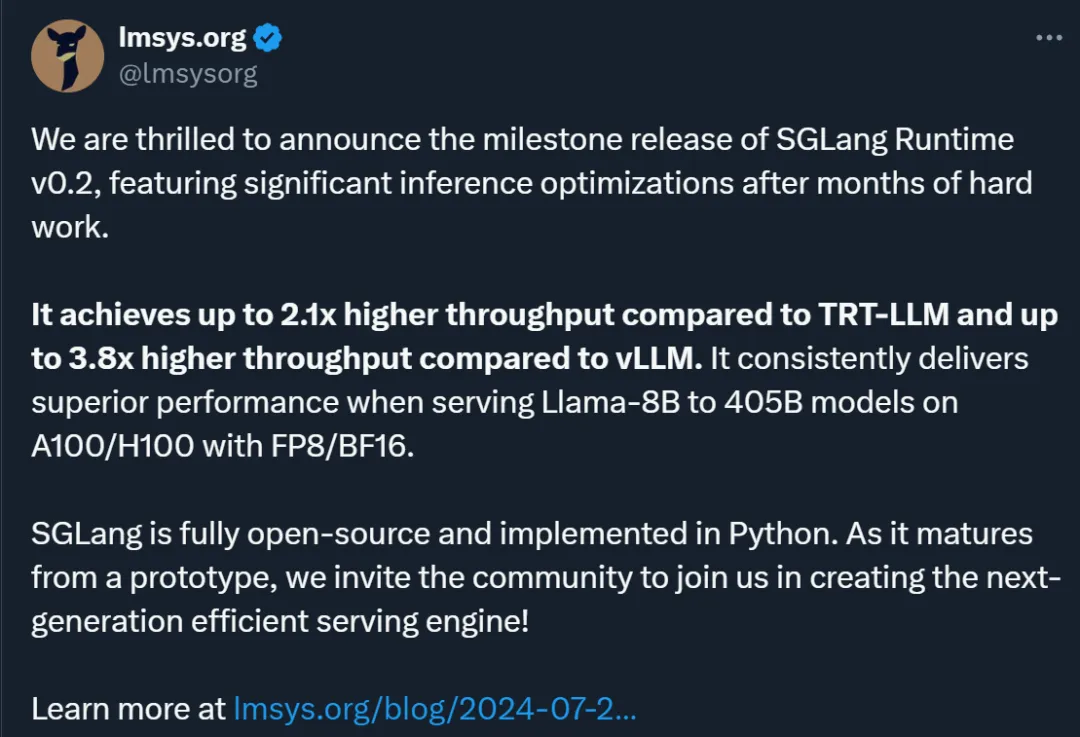
用来运行 Llama 3 405B 优势明显。